
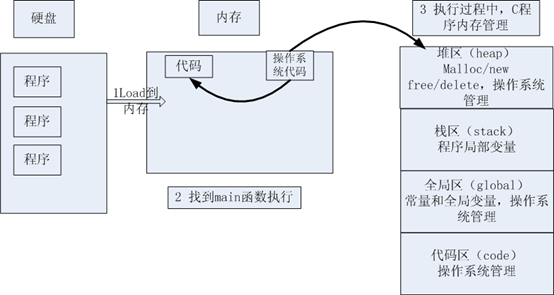
内存四区的建立流程
在Python中有一些内置的方法,这些方法命名都有比较特殊的地方(其方法名以2个下划线开始然后以2个下划线结束)。类中最常用的就是构造方法和析构方法。
构造方法__init__(self,….):在生成对象时调用,可以用来进行一些初始化操作,不需要显示去调用,系统会默认去执行。构造方法支持重载,如果用户自己没有重新定义构造方法,系统就自动执行默认的构造方法。
析构方法__del__(self):在释放对象时调用,支持重载,可以在里面进行一些释放资源的操作,不需要显示调用。
类初始化时构造函数调用顺序:
(1)初始化对象的存储空间为零或null值;
(2)调用父类构造函数;
(3)按顺序分别调用类成员变量和实例成员变量的初始化表达式;
(4)调用本身构造函数。
图片加载几乎是任何 Android 项目中必备的需求,而图片加载的开源库也越来越多,我们姑且在 GitHub 上搜索下 android image 关键字,出来的前五个按照 Star 数排序的项目如下:
可以看到前四个是大家比较熟知的图片加载库,有 UniversalImageLoader、Picasso、Fresco、Glide,至于第五个 ion 其实是一个网络库,只不过也提供了图片加载的功能,跟 Volley 类似,也提供图片加载的功能,但是如果图片加载是一个强需求的话,我更喜欢专注的库,所以本文只讨论单纯的图片加载库。
strcpy: 最常用的字符串拷贝函数,但是要注意这个函数不会自己判断源字符串是否比目标空间大,必须要程序员自己检查,否则很容易造成拷贝越界,下面是几个例子:
char *a = "0123456789", *b = "abcdefghijk";
char c[5];
输出: strcpy(c,a)=0123456789 //数组c只有5个字节的空间,但是经过strcpy后a的剩余字符也拷贝过去了,如果c后面是系统程序空间,那就要出问题了。